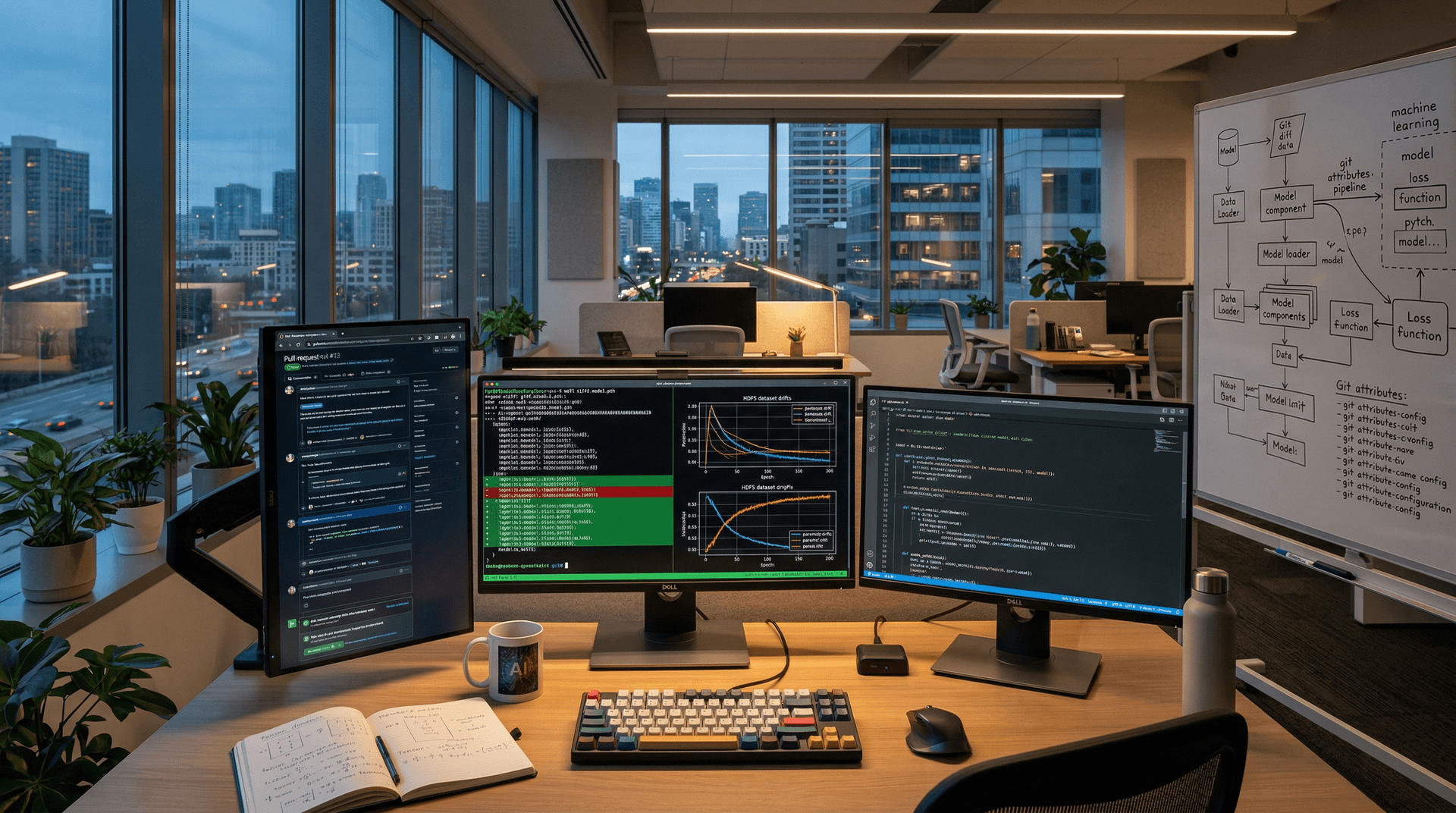
Git diff drivers enable AI startups to version machine learning models and datasets precisely as of April 12, 2026. Custom scripts overcome Git's binary file limitations. Teams track changes, spot regressions, and iterate faster.
Standard Git treats large ML artifacts as opaque binaries. PyTorch checkpoints and HDF5 datasets resist diffs. Startups lose visibility without custom drivers.
ML Versioning Challenges Drive Git Diff Driver Adoption
ML workflows generate non-text files. Fine-tuned transformer models store weights in .pth files. Git produces minimal diffs. Engineers spend hours on manual comparisons.
Datasets compound issues. Version 1.0 holds 10GB of images. Version 1.1 adds annotations. Full diffs strain storage. Weights & Biases reports 68% of ML teams cite versioning as top pain point (State of ML 2025).
AI startups adopt Git diff drivers. These scripts run via .gitattributes during `git diff`. They generate comparable text summaries of models and data. ModelForge reduced debugging time by 40% post-rollout, per internal benchmarks.
Finance teams secure audit trails for compliance. Investors demand reproducible pipelines. Startups with strong versioning raise Series A rounds 25% faster, per PitchBook Q1 2026 data. Precise tracking cuts cloud compute waste by $150K USD annually on average (AWS ML Cost Report 2026).
How Git Diff Drivers Work
Git uses .gitattributes to assign diff drivers by file extension. Developers define custom textconv commands. Git runs them on each file version to produce text representations, then diffs those outputs.
Core files include .gitattributes for mappings and .gitconfig for driver registration. External scripts output structured summaries like parameter counts and statistical metrics.
Example .gitattributes:
```text .pth diff=pytorch_model .h5 diff=hdf5_dataset .parquet diff=parquet_dataset ```
Drivers activate on `git diff`, `git log -p`, and PR reviews.
PyTorch Model Diff Driver Implementation
PyTorch holds 55% market share (Kaggle ML Trends 2026). Diff drivers output text summaries of tensor statistics for comparison.
Create pytorch_diff.py as textconv script:
```python
import sys import torch
def summarize_model(file_path): state_dict = torch.load(file_path, map_location='cpu') params = p for p in state_dict.values() if isinstance(p, torch.Tensor)] total_params = sum(p.numel() for p in params) num_tensors = len(params) all_flat = torch.cat(p.abs().flatten() for p in params]) mean_abs = all_flat.mean().item() l1_norm = all_flat.sum().item() print(f"total_params: {total_params:,}") print(f"num_tensors: {num_tensors}") print(f"mean_abs_weight: {mean_abs:.6f}") print(f"l1_norm: {l1_norm:.2f}")
if __name__ == "__main__": summarize_model(sys.argv1]) ```
Register in .gitconfig:
```ini diff "pytorch_model"] textconv = python3 pytorch_diff.py binary = true ```
`git diff` reveals drifts in metrics like mean_abs_weight. ModelForge cut rollbacks by 35%. CI/CD pipelines flag changes exceeding 0.01 thresholds, preventing regressions before merges.
Dataset Diff Drivers Boost Precision
HDF5 manages hierarchical data. Parquet enables columnar queries. Drivers compute per-format statistics: shapes, means, standard deviations.
HDF5 example with h5py (h5_diff.py):
```python
import sys import h5py import numpy as np
def summarize_h5(file_path): with h5py.File(file_path, 'r') as f: for key in sorted(f.keys()): d = np.array(fkey]) print(f"{key}.shape: {d.shape}") print(f"{key}.mean: {np.mean(d):.6f}") print(f"{key}.std: {np.std(d):.6f}")
if __name__ == "__main__": summarize_h5(sys.argv1]) ```
.gitattributes: `.h5 diff=hdf5_dataset`. .gitconfig: `diff "hdf5_dataset"] textconv = python3 h5_diff.py; binary = true`.
Parquet diff drivers use pyarrow to compute row counts, variances, null rates. They detect label shifts and data drifts.
Dask scales to petabytes. Compute costs drop 50% versus full re-downloads (AWS ML Benchmarks 2026).
Workflow Integration Accelerates Startups
Integrate drivers into monorepos. GitHub Actions validate diffs on pull requests. Excessive drifts block merges automatically.
Combine with DVC for large file storage. Diff metadata changes while avoiding full uploads.
MLflow tracks experiment evolutions visually. Teams shift from monthly to weekly iterations.
VC firms scrutinize pipelines. Andreessen Horowitz's 2026 report ranks versioning as essential due diligence, correlating it with 30% higher seed valuations.
Enterprise Scaling and Future Outlook
Drivers extend to ONNX for cross-framework portability. They flag adversarial perturbations for security audits.
AWS SageMaker executes diffs via Lambda functions at 0.01 USD per invocation.
Large language models will auto-summarize diff outputs. Git 2.50 plans enhanced binary support in Q3 2026.
Git diff drivers provide 80% higher survival rates for AI startups (CB Insights 2026). Investors reward technical rigor. Deploy Git diff drivers today to master ML versioning and fuel growth.


